

What Is Orpheus TTS?
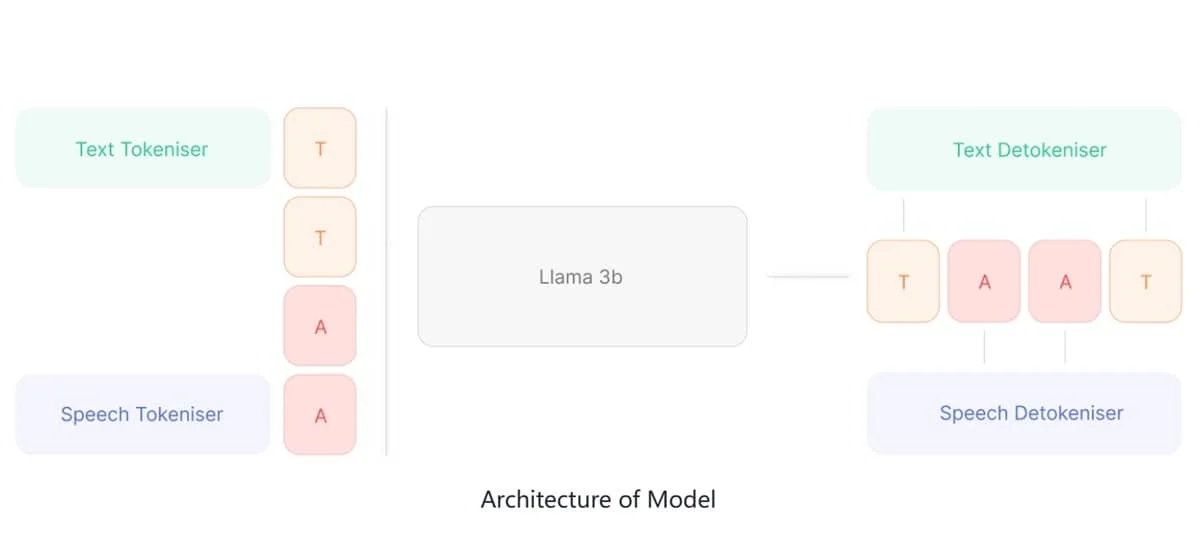
Orpheus TTS is an open-source text-to-speech AI model, built on the foundation of the Llama-3b architecture. This innovative system demonstrates the emerging capabilities of leveraging Large Language Models (LLMs) for speech synthesis, pushing the boundaries of what’s possible in AI-generated voice technology.
Core Capabilities of Orpheus TTS
1. Human-Like Speech
Orpheus TTS delivers natural intonation, emotional depth, and rhythm that surpasses even proprietary state-of-the-art models.
2. Zero-Shot Voice Cloning
Replicates voices without requiring pre-fine-tuning, offering unprecedented flexibility.
3. Controllable Emotion and Tone
Orpheus TTS allows simple tag-based control over speech characteristics and emotional qualities.
4. Minimal Latency
Achieves streaming latency of approximately 200ms for real-time applications, with input streaming potentially reducing this to around 100ms.
Model Variants
The Orpheus team has released a comprehensive range of models based on the Llama architecture, available in four different sizes:
- Medium: 3 billion parameters
- Small: 1 billion parameters
- Tiny: 400 million parameters
- Nano: 150 million parameters
What’s particularly impressive is that even the smallest models demonstrate exceptional quality and aesthetically pleasing voice generation.
Technical Implementation
Orpheus TTS comes with a streamlined Python package that facilitates real-time streaming. For the 3 billion parameter model, streaming inference outpaces playback speed even on a 40GB A100 GPU.
Training Methodology of Orpheus TTS
The pre-trained models utilize Llama-3b as their backbone architecture. They’ve been extensively trained on over 100,000 hours of English speech data combined with billions of text tokens. This text token training significantly enhances the model’s performance on TTS tasks by strengthening its language comprehension capabilities.